Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM

Search engines crawl the content of web pages through web spiders and display them in relevant search results. But some web content we may not want to be indexed and indexed by search engines.
We can declare to allow/forbid search engine spiders to crawl certain directories or web pages through the robots.txt file, thereby limiting the scope of search engines’ inclusion.
This article introduces how to configure and use the robots.txt file of the website, and how to write the robots.txt file.

robots.txt is a plain text file stored in the root directory of the website, which is used to tell web spiders what content on this site is allowed to crawl and what content is not allowed to crawl.
When a search engine’s spider visits a website, it will first check the robots.txt file of the website to obtain the scope of crawling allowed on the website.
It should be noted that robots.txt is just a customary rule, not mandatory, and some search engines do not support it, so it cannot guarantee that the web content will/will not be crawled.
user-agent: googlebot
disallow: /tag/news
If the website does not have a robots.txt file, it can be manually created and uploaded to the root directory of the website; even if there are no pages that need to be blocked from search engines, it is recommended to add an empty robots.txt file.
Please pay attention to the difference between “only”, “allowed” and “prohibited” in the text!
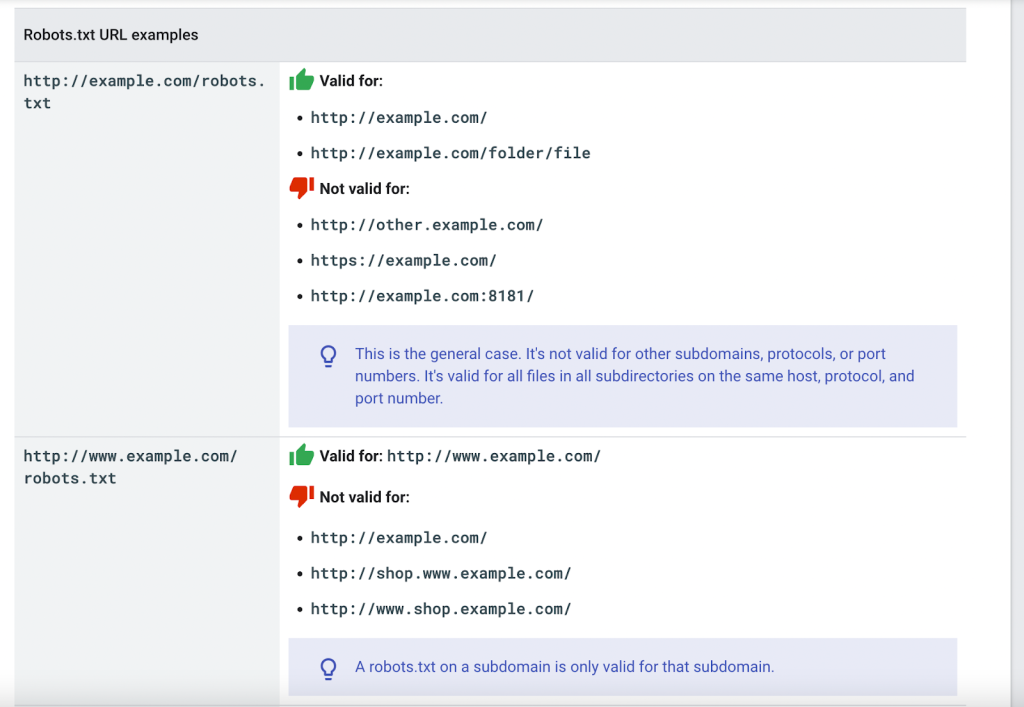
Path matching example: (↓ Screenshot from Google Developers)
# Common search engine spider (robot) name